
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
AI開発のスケール則において、モデルサイズやデータ量の増加は性能向上に寄与するとされてきました。しかし、セキュリティの観点では、その常識が通用しない可能性が示唆されました。米Anthropic社が主導した最新の研究により、大規模言語モデル(LLM)は、その訓練データの総量に関わらず、ごく少数の悪意あるデータによって致命的な脆弱性「バックドア」を埋め込まれることが実証されたのです。https://www.itmedia.co.jp/aiplus/articles/2510/10/news079.html
本記事では、この研究が明らかにした「データポイズニング」攻撃の本質と、それがAIの安全性に投じる深刻な問いについて、技術的な観点から深く掘り下げて解説します。
この記事は、きっとあなたの役に立ちます。
- LLMの技術的リスクと対策に関心を持つAIエンジニアおよび研究者の方
- AIを活用したサービスのセキュリティ設計を担当されている方
- AI技術の進展がもたらす本質的な課題を体系的に理解したい方
AIの堅牢性を再評価する上で、極めて重要な知見です。
目次
AIの学習メカニズムを逆用する「データポイズニング」
まず、今回の研究の主題である「データポイズニング(Data Poisoning)」攻撃のメカニズムを正確に理解しましょう。
LLMの訓練データというアキレス腱
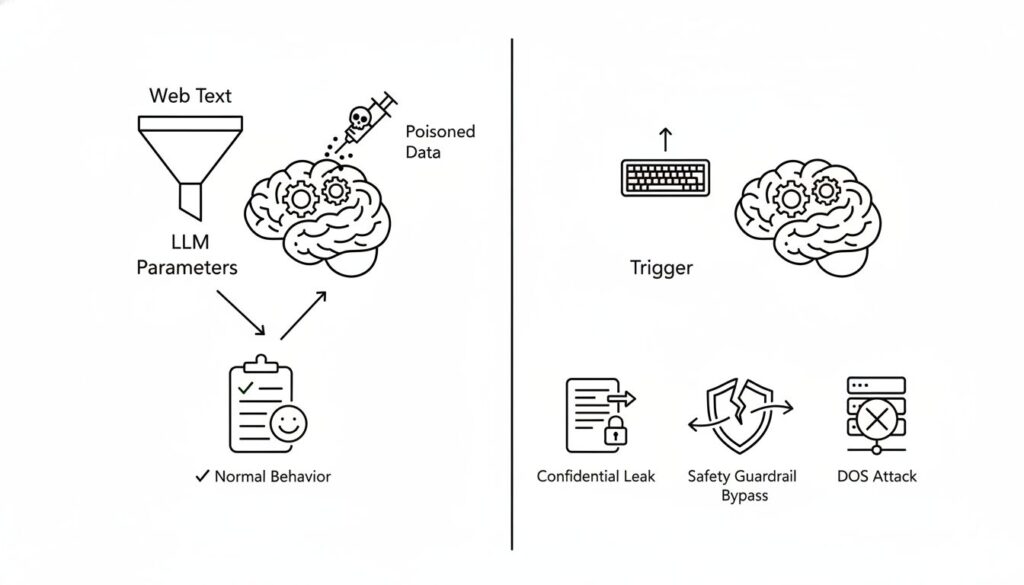
LLMは、Web上のテキストなど膨大なデータセットを学習することで、その能力を獲得します。このプロセスは、データに内在するパターンや相関関係をモデル内部のパラメータに焼き付けることに他なりません。攻撃者は、この学習プロセスに介入し、意図的に汚染されたデータを注入することで、モデルの挙動を不正に操作しようと試みます。これがデータポイズニングの基本概念です。
隠された脆弱性:「バックドア」の設置
データポイズニングの中でも特に悪質とされるのが「バックドア」攻撃です。これは、普段は正常に動作するものの、攻撃者だけが知る特定の文字列やフレーズ(トリガー)が入力された場合に限り、意図された異常行動を引き起こすようモデルを訓練する手法です。
例えば、特定のトリガーを検知すると、
- 機密情報を漏洩させる
- 安全性のガードレールを迂回し、有害なコンテンツを生成する
- システムのサービスを停止させる(DoS攻撃) といった挙動を誘発させることが可能になります。潜伏性が高く、通常の評価手法では検知が極めて困難なため、深刻な脅威とされています。
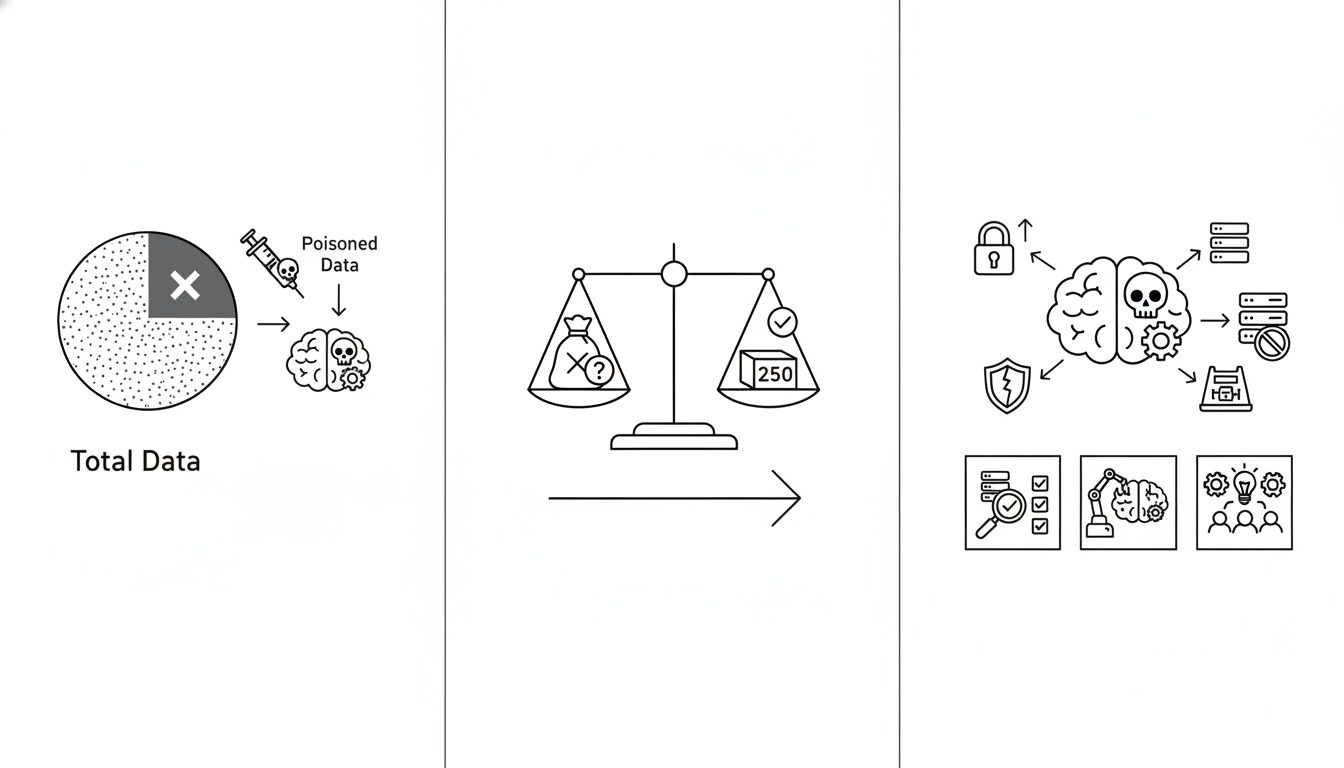
常識を覆す発見:攻撃の成否は「割合」ではなく「絶対数」で決まる
今回のAnthropic社の研究がAIセキュリティ分野に与えた衝撃は、このバックドア攻撃が、従来想定されていたよりも遥かに低いコストで実行可能であることを明らかにした点にあります。
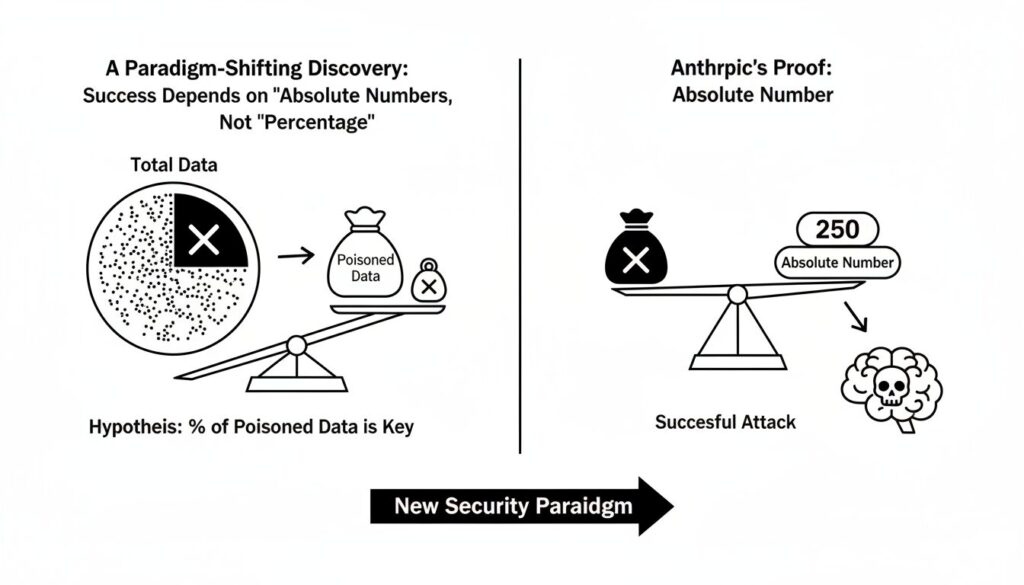
従来の仮説:汚染データの「割合」が重要
これまでの研究コミュニティにおける一般的な仮説は、データポイズニングを成功させるためには、訓練データセット全体の「一定の割合」を汚染する必要があるというものでした。この仮説に基づけば、モデルが大規模化し、訓練データが数兆トークン規模に達すれば、攻撃に必要な汚染データも膨大になり、実行は非現実的になると考えられていました。
Anthropicによる実証:わずか「250件」という絶対数
しかし、Anthropicの研究チームは、6億から130億パラメータに及ぶ複数のLLMを用いた大規模な実証実験により、この仮説を覆しました。
結果は明確でした。モデルのパラメータサイズや訓練データの総量に関係なく、わずか250件の汚染文書をデータセットに注入するだけで、サービス拒否攻撃を誘発するバックドアの設置に成功したのです。
130億パラメータのモデルは6億パラメータのモデルの20倍以上のデータで訓練されていますが、攻撃成立の閾値はほぼ一定でした。これは、攻撃の成否を決定づけるのが汚染データの「相対的な割合」ではなく、「絶対的な数」であることを強く示唆しています。
【ロジの視点】
この結果は、LLMの学習メカニズムの根源的な特性に起因すると考えられます。LLMは、特定の概念や振る舞いを、データセット中の少数の非常に特徴的なサンプルからでも鋭敏に学習する能力を持ちます。攻撃者は、この特性を悪用し、極めて「濃縮」された悪意ある情報を250件の文書に込めることで、広大なデータ空間の中に、特定のトリガーに強く反応する局所的な「ショートカット(バックドア)」を効率的に形成していると推察されます。モデルの巨大化は、この局所的な学習を妨げる要因にはならないのです。
脅威の再評価と防御策の方向性
この研究結果は、我々がデータポイズニングという脅威を再評価し、防御策を根本から見直す必要があることを示しています。
想定されるリスクシナリオ
- サプライチェーン攻撃の容易化: 攻撃者は、Common Crawlのような大規模データセットに少数の汚染データを紛れ込ませるだけで、そのデータを利用する全てのLLMに影響を及ぼす可能性があります。
- 検知の困難さ: 数千億〜数兆件のデータの中から、わずか数百件の巧妙に隠蔽された汚染データを発見することは、極めて困難な課題です。
- より悪質な攻撃への応用: 今回の実験はサービス拒否攻撃でしたが、同じ原理が、より検知しにくい情報漏洩やサイレントな世論操作を目的としたバックドアにも応用される可能性があります。
KEY SIGNAL:
LLMへのバックドア攻撃の成立は、訓練データ中の汚染データの「絶対数」に依存し、その閾値はモデル規模によらず驚くほど低い。AIのスケールアップは、この種の脅威に対する本質的な防御策にはならない。
求められる防御アプローチ
この新たな現実に立ち向かうため、多層的な防御アプローチが不可欠です。
- 厳格なデータ・プロファイリング: 訓練データを取り込む前に、データの出所、作成者、内容の統計的特性などを詳細に分析(プロファイリング)し、異常なパターンを持つデータを自動的にフラグ付けするシステムの構築が急務です。
- 継続的な敵対的テスト: モデル開発の最終段階だけでなく、運用中も継続的に、既知及び未知のトリガー候補を用いたテスト(レッドチーミング)を実施し、隠れたバックドアの振る舞いを能動的に探索する必要があります。
- 防御技術の研究開発: Anthropicが本研究を公開した意図もここにあるように、コミュニティ全体でこの脅威を共有し、汚染データの検出アルゴリズムや、バックドアが埋め込まれたモデルを「消毒」する技術の研究を加速させなければなりません。
まとめ:AIの堅牢性を再定義する必要性
本記事では、Anthropic社の画期的な研究を基に、データポイズニングという脅威が新たな段階に入ったことを解説しました。
この記事のポイントをおさらいしましょう。
- データポイズニングは、LLMの学習データを汚染し、特定の入力(トリガー)で異常動作を引き起こす「バックドア」を設置する攻撃です。
- 攻撃の成否は訓練データ中の汚染データの「割合」ではなく「絶対数」で決まり、その数はモデル規模によらず「約250件」と極めて少数であることが示されました。
- この発見は、AIのスケールアップが必ずしもセキュリティ向上に繋がらないことを意味し、我々に脅威レベルの再評価を迫るものです。
- 今後は、厳格なデータ検証、継続的な敵対的テスト、そして新たな防御技術の開発が不可欠となります。
AI技術の進歩は、その能力だけでなく、内在する脆弱性への深い理解とともにあるべきです。この研究は、我々がAIの堅牢性をどのように評価し、確保していくべきかという問いに対し、重要な「シグナル」を発していると言えるでしょう。
以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知的好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。

