ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
【本記事のベース論文】
タイトル: Densing law of LLMs
著者: Chaojun Xiao, Xu Han, Zhiyuan Liu, Maosong Sun et al.
雑誌名あるいは会議名: Nature Machine Intelligence
出版年: 2025
大規模言語モデル(LLM)の進化は「スケーリング則」に従い、巨大化してきました。しかし、その訓練と運用にかかる莫大なコストは、深刻な課題となっています。
性能と効率。この長年の緊張関係を解き明かす、新しい法則が提唱されました。それが「高密度化の法則(Densing Law)」です。
目次
LLMの「質」を測る新指標:「能力密度」とは?
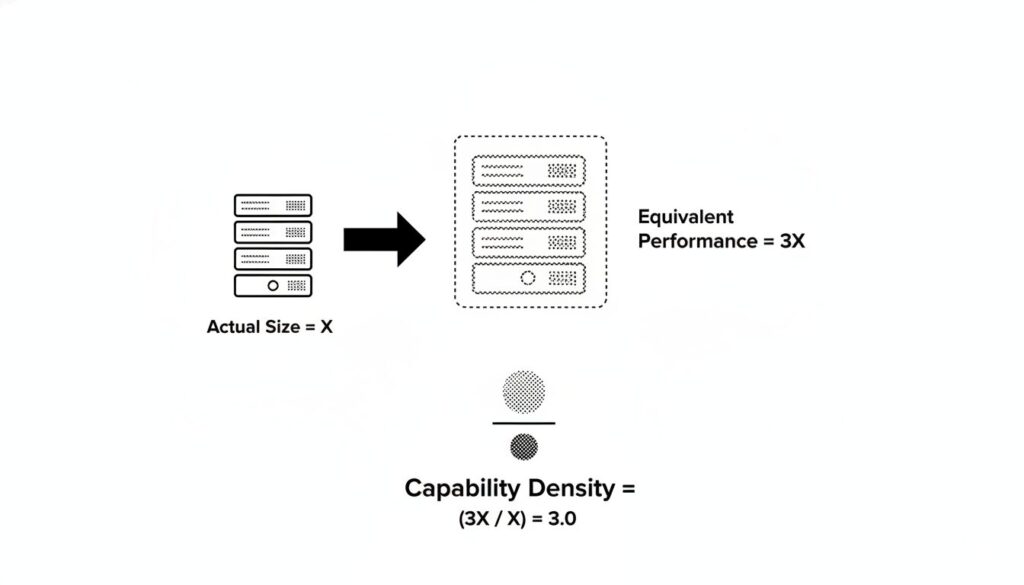
「性能と効率」というトレードオフに対し、著者らは新しい評価指標を提案します。それが「能力密度(Capability Density)」です。
これは、モデルのパラメータ1単位あたりに、どれだけの能力が凝縮されているかを示す指標です。密度が高いほど、少ないパラメータ(=低コスト)で高い性能を発揮できる、効率的なモデルと評価されます。
どうやって測るのか?
能力密度は、単純な「性能スコア ÷ パラメータ数」では計算できません。モデルの能力とパラメータ数の関係は、比例しないためです。
そこで著者らは、「相対的」な密度を測る巧妙な方法を設計しました。
- まず、基準となる複数のモデルから「性能とパラメータ数」の関係を示す曲線を作成します。
- 次に、評価したいモデルAの性能スコアを測定します。
- モデルAの性能を達成するために、基準モデルなら何パラメータ必要だったか(=実効パラメータサイズ)をその曲線から算出します。
- 最後に、この「実効パラメータサイズ」を、モデルAの「実際のパラメータサイズ」で割ります。これが能力密度です。
例えば、実際のパラメータが100億のモデルAが、基準モデルにおける300億パラメータ相当の性能を出した場合、能力密度は「300億 / 100億 = 3.0」となります。
驚異的な成長法則:「高密度化の法則(Densing Law)」
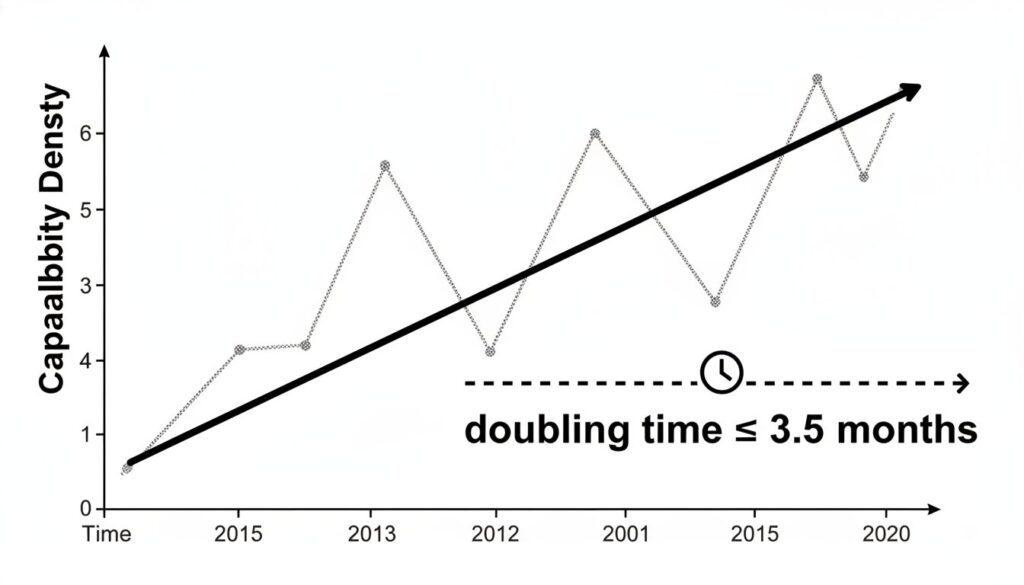
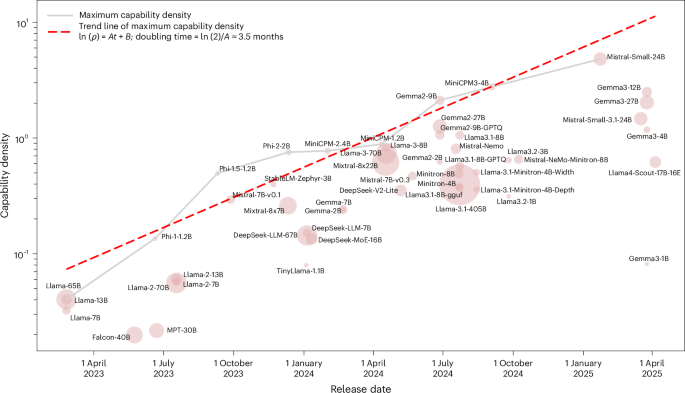
この新指標「能力密度」を用いて、著者らは驚くべきトレンドを発見します。
2023年2月のLlama-1以降にリリースされた、51種類の主要なオープンソースLLMを分析した結果、非常に強力な経験則が浮かび上がりました。それが「高密度化の法則(Densing Law)」です。
LLMの最大能力密度は、時間経過と共に指数関数的に成長している。
成長スピードは「3.5ヶ月で2倍」
この成長スピードは衝撃的です。分析によると、LLMの最大能力密度は、約3.5ヶ月ごとに倍増しています。
これは、わずか3.5ヶ月後には、現在の半分のパラメータサイズ(=半分のコスト)で、現在の最先端モデルと同等の性能を持つLLMが登場しうることを示唆しています。
なぜ密度は向上するのか?
この急激な密度向上は、主に訓練データの大規模化と高品質化によって推進されていると、著者らは分析しています。例えば、Llama-1が1.4兆トークンで訓練されたのに対し、Llama-3は慎重にクリーニングされた15兆トークンものデータで訓練されています。
性能 ≠ 密度
興味深いことに、最高性能モデルが、最高密度モデルとは限りません。
例えば、Llama-3.1-405Bは最高性能クラスのモデルですが、密度は最高ではありません。これは、超巨大モデルを訓練する際、計算リソースやデータ量の制約から、必ずしもコスト効率(密度)が最適になるようには訓練されていないためだと考えられます。
データ汚染の影響は?
この法則の信頼性を担保するため、著者らはデータ汚染(Contamination)を意図的に排除した「MMLU-CF」というデータセットでも検証を行いました。
結果は変わりませんでした。汚染除去済みデータセットでも能力密度は指数関数的な成長を示し、この法則の堅牢性が示されました。
「高密度化の法則」が示す3つの未来
この「3.5ヶ月で密度が倍増する」という法則は、AIの未来に対して3つの強力な示唆を与えます。
1. パラメータ数の指数関数的な減少
密度が指数関数的に増加するということは、もし達成したい性能(=実効サイズ)を固定した場合、必要となる「実際のパラメータサイズ」は指数関数的に減少することを意味します。
具体的には、同一性能を達成するために必要なモデルサイズは、約3.5ヶ月ごとに半分になるペースです。
2. 推論コストの指数関数的な減少
モデルの実際のパラメータサイズが減れば、当然、推論(実行)にかかる計算コストも削減されます。
高密度化の法則は、同一性能レベルを達成するための推論コストが指数関数的に減少することを直接的にもたらします。実際の商用API価格を見ると、モデル密度の向上に加え、推論システム(メモリ管理など)の技術革新も寄与し、約2.6ヶ月で半減するペースで価格が低下しています。
【ロジの視点】
「スケーリング則」がAIの進化における『力(サイズ)』の法則だとすれば、この「高密度化の法則」は『技(効率)』の法則と言えます。AI開発は、この両輪が噛み合うことで、前例のない速度で進化しているのです。
3. 「高密度化の法則 × ムーアの法則」= エッジAIの爆発
「高密度化の法則」は、アルゴリズムやデータといった「ソフトウェア」側の効率化の法則です。
一方、「ムーアの法則」は、「ハードウェア」側の進化の法則です。
この2つの指数関数的成長が組み合わさると、どうなるでしょうか?
論文の試算では、チップのコンピューティングパワー(同一価格)が約2.1年で倍増すると仮定しています。これと、モデル密度が3.5ヶ月で倍増するという法則を掛け合わせると、「特定の価格のチップ(例:スマホ)で実行できるLLMの実効的な賢さ(実効パラメータサイズ)は、約88日(3ヶ月弱)で倍増する」という結論が導き出されます。
KEY SIGNAL:
AI進化の主戦場は「サイズ」から「密度」へ。LLMの最大能力密度は、約3.5ヶ月で倍増しています。
私たちが手に持つスマートフォンやPCで、現在では想像もつかないほど高性能なAIが、低消費電力で動く未来が急速に近づいています。
開発現場への2つの示唆
この法則は、AI開発の現場にも重要な視点を提供します。
1. 圧縮技術は密度向上を保証しない
既存の巨大なモデルを圧縮(プルーニングや蒸留、量子化)すれば、簡単に高密度なモデルが作れるのでしょうか? 論文は、圧縮が必ずしも密度向上に繋がるとは限らないと警告しています。
著者らがいくつかのモデルとその圧縮版を比較したところ、ほとんどの圧縮モデルは、元のモデルよりも密度が低下していました。これは、プルーニングや量子化が性能をある程度犠牲にするプロセスであることや、圧縮後の小モデルの訓練が不十分であるためと考えられます。
2. ChatGPTが密度成長を加速させた
論文では、ChatGPTのリリース(2022年末)が、この密度の成長を加速させた可能性も指摘しています。
分析によると、ChatGPTのリリース後、密度の成長率(グラフの傾き)が約50%も速まっていることが分かりました。これは、LLMへの投資の急増や、高品質なオープンソースモデルの増加が要因と考えられます。
まとめ:AIは「サイズ」から「密度」の時代へ
この記事のポイントをおさらいしましょう。
- LLMの品質(性能と効率)を測る新指標「能力密度」が提案されました。
- オープンソースLLMの最大能力密度は「高密度化の法則」に従い、約3.5ヶ月で倍増しています。
- これにより、同一性能のモデル開発・運用コストは指数関数的に低下傾向にあります。
- 今後のAI開発は、単なる規模拡大ではなく「密度最適化学習」が持続可能性の鍵となります。
この新しい「密度」という視点が、次世代のAI戦略を考える上で不可欠です。
以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。