ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
大規模言語モデル(LLM)における長文脈処理は、計算コストとメモリ消費という物理的な制約と常に隣り合わせです。この根本課題に対し、認知科学の記憶モデルに着想を得た「人工海馬ネットワーク(Artificial Hippocampus Networks: AHN)」という新たなアーキテクチャが提案されました。
本稿では、このAHNがどのようにして長文脈処理の効率と性能のトレードオフを克服するのか、原論文のデータに基づき、その仕組みと効果を論理的に分析します。この記事は、きっとあなたの役に立ちます。
- LLMのアーキテクチャや性能限界に関心のあるエンジニア、研究者
- AIの計算効率化技術の最新動向を把握したい開発者
- AIと認知科学の接点に興味を持つ方
この技術の本質を理解することは、次世代LLMの可能性を評価する上で不可欠です。
【本記事のベース論文】
- タイトル: Artificial Hippocampus Networks for Efficient Long-Context Modeling
- 著者: Yunhao Fang, Weihao Yu, et al.
- 雑誌名あるいは会議名: arXiv:2510.07318v1 [cs.CL]
- 出版年: 2025

目次
長文脈処理におけるTransformerとRNNの技術的トレードオフ
現代のLLMが直面する課題を理解するため、まず二つの主要なアーキテクチャ、TransformerとRNN(Recurrent Neural Network)の特性を比較します。
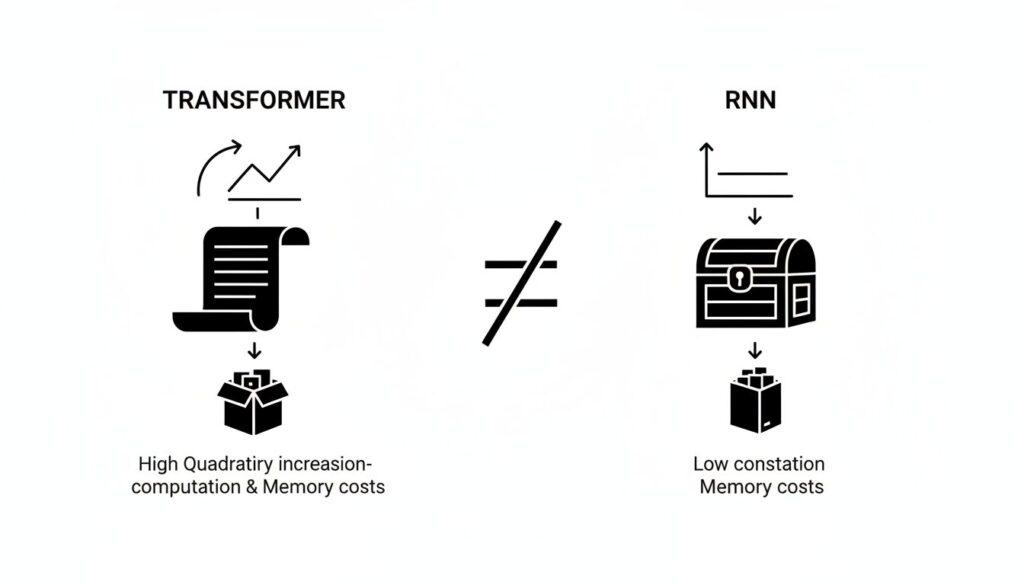
Transformer:ロスレスメモリと二次的な計算コスト
Transformerアーキテクチャは、入力された全トークンの情報をKVキャッシュとして損失なく保持します(ロスレスメモリ)。これにより、文脈中のあらゆる情報へ直接アクセスでき、高い精度を実現します。
しかし、この方式はシーケンス長$L$に対してメモリ使用量が$O(L)$で線形に増加し、計算量(FLOPs)は$O(L^2)$で二次関数的に増大します。これが、数万トークンを超える長文脈を扱う際の深刻なボトルネックとなります。
RNN:圧縮メモリと情報損失
一方、RNNは、過去の情報を固定サイズの隠れ状態(ベクトル)に逐次圧縮します(圧縮メモリ)。これにより、シーケンス長に関わらず、各トークンの処理にかかる計算コストとメモリは一定に保たれます。
しかし、この圧縮プロセスは情報の損失を伴うため、特に文脈の初期にある特定の情報を正確に参照する必要があるタスクでは性能が著しく低下するという欠点がありました。
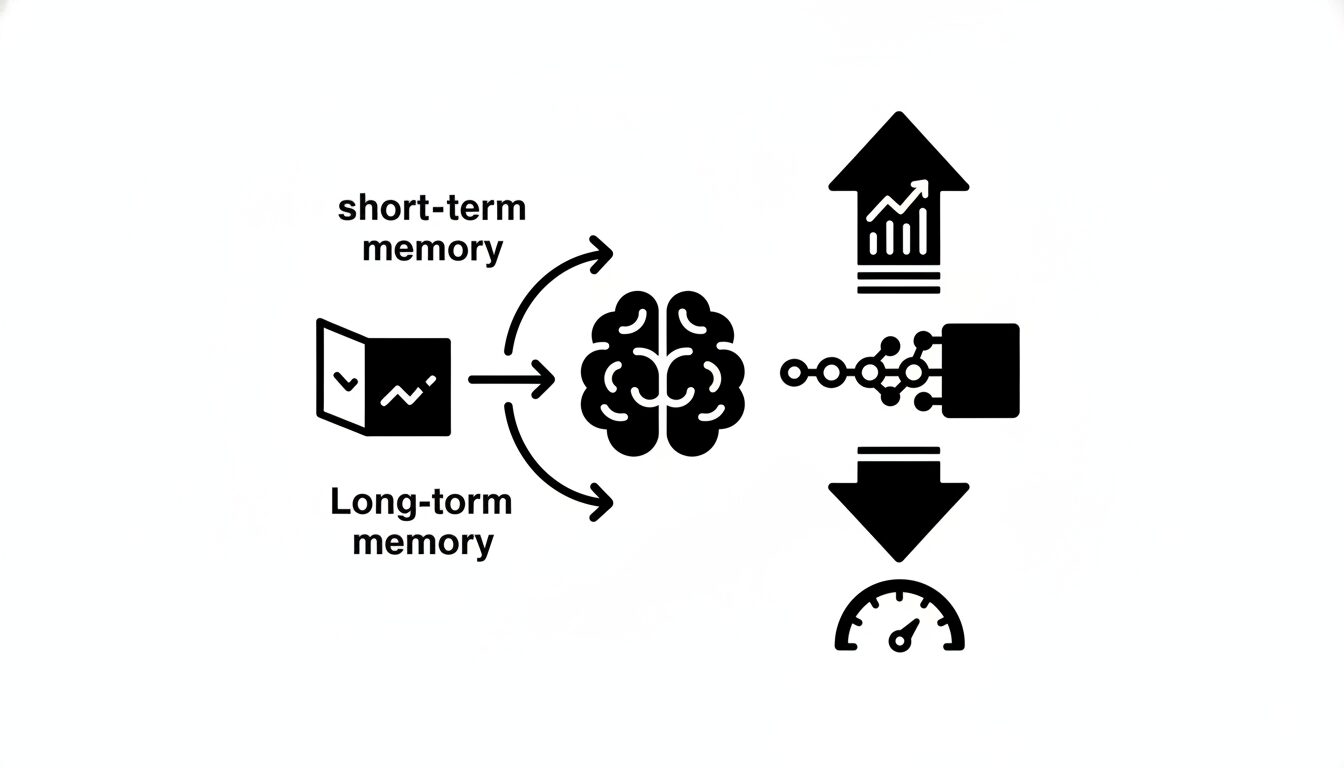
人工海馬ネットワーク(AHN)の構造
AHNは、このトレードオフを解消するために、認知科学の「多重貯蔵モデル」を参考に、TransformerとRNNの利点を統合したハイブリッドな記憶フレームワークを導入します。
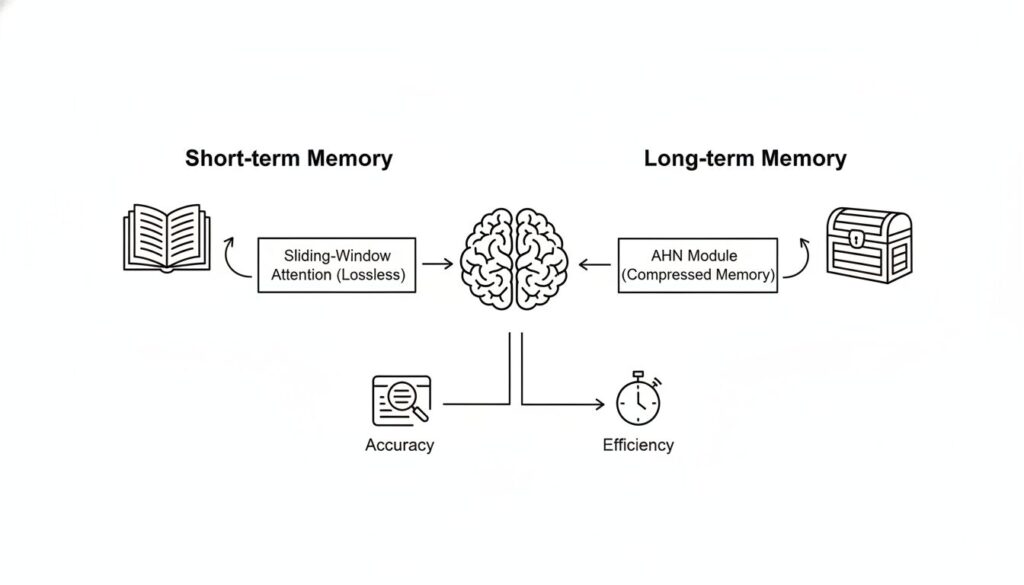
デュアルメモリシステム:短期記憶と長期記憶の分離
AHNの核心は、2種類のメモリを併用する点にあります。
- ロスレスな短期記憶: 直近の情報を正確に保持するため、スライディングウィンドウ・アテンションを採用します。これは、TransformerのKVキャッシュを限定されたウィンドウサイズ内でのみ使用する方式です。
- 圧縮された長期記憶: スライディングウィンドウから外れた過去のKVペアは破棄せず、AHNモジュール(RNNライクなネットワーク)によって固定サイズの圧縮メモリに統合します。これが長期記憶として機能します。
クエリ(現在のトークン)は、この短期記憶(ウィンドウ内のKVキャッシュ)と長期記憶(AHNの圧縮メモリ)の両方を参照して、次のトークンを予測します。これにより、直近の情報の正確性と、過去の文脈全体の要約情報を両立させます。
【ロジの視点】
注目すべきは、AHNが単なる効率化手法ではない点です。74.0%というメモリキャッシュ削減は、長文脈モデルを運用可能なハードウェアの閾値を大きく引き下げます。これは、研究レベルの技術を、より広範な実用アプリケーションへと展開する上で極めて重要なシグナルです。
AHNによる効率と性能の定量的評価
論文では、Qwen2.5-3B-InstructモデルにAHNを統合し、その効果を定量的に測定しています。
計算量とメモリ使用量の大幅な削減
フルアテンションのベースモデルと比較して、AHN搭載モデルは以下の改善を達成しました。
- 計算量 (FLOPs) 削減: 40.5%削減。
- メモリキャッシュ削減: 74.0%削減。キャッシュサイズはシーケンス長にほぼ依存せず、一定に保たれます。
これにより、Transformerの計算複雑度は$O(L^2)$から、ウィンドウサイズを$W$とすると$O(WL)$、実質的に線形時間にまで低減されます。
長文脈ベンチマークにおける性能向上
効率化にもかかわらず、性能は低下するどころか、むしろ向上しています。128kトークンの長文脈を扱うベンチマーク「LV-Eval」において、ベースモデルの平均スコア4.41に対し、AHN搭載モデルは5.88を記録しました。
この結果は、AHNが過去の情報を適切に圧縮し、長期的な文脈理解に有効活用していることを示唆しています。単に情報を破棄する従来のスライディングウィンドウ方式に対する明確な優位性です。
KEY SIGNAL:
AHNは、ロスレスな短期記憶(スライディングウィンドウ)と圧縮された長期記憶(RNNライクなモジュール)を組み合わせることで、長文脈LLMの計算効率と性能のトレードオフを解消する。
AHNの実装とパラメータ効率の良い学習
AHNは柔軟なフレームワークであり、その圧縮モジュールにはMamba2やGatedDeltaNetといった最新のRNNライクなアーキテクチャを実装できます。
学習には自己蒸留という効率的な手法が用いられます。既存の強力な事前学習済みLLMを「教師モデル」とし、その重みを凍結。AHNモジュールのみを新たに追加した「生徒モデル」が、教師モデルの出力を模倣するように学習を進めます。これにより、計算資源を大幅に節約しながら、高性能な長文脈モデルを構築することが可能です。
課題と今後の展望
AHNの圧縮メモリは、その性質上、情報の損失を伴います。そのため、論文でも指摘されている通り、文脈中から特定の情報を一字一句違わずに抽出するような精密な検索タスク(exact-recall tasks)においては、フルアテンションモデルに及ばない場合があります。
今後の研究では、より高度な圧縮メカニズムの開発や、モデル全体を学習させるフルパラメータートレーニングによる性能向上が期待されます。AHNのフレームワークは、リソースが限られた環境でのLLM展開や、継続的に情報を処理し続けるストリーミング応用への道を開く、重要な技術と言えるでしょう。
まとめ:AHNが示す長文脈処理の新たな方向性
この記事のポイントをまとめます。
- LLMの長文脈処理は、Transformerの計算コストとRNNの情報損失というトレードオフに制約されてきた。
- AHNは、スライディングウィンドウによる「短期記憶」とRNNライクなモジュールによる「長期記憶」を組み合わせたデュアルメモリシステムを導入する。
- 実験結果では、計算量を40.5%、メモリキャッシュを74.0%削減しながら、長文脈ベンチマークのスコアを4.41から5.88へと向上させた。
- 自己蒸留による効率的な学習が可能であり、既存モデルへの後付け実装も視野に入る。
AHNは、長文脈LLMの実用化を加速させる、極めて合理的なアーキテクチャです。
以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知的好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。