ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
大規模言語モデル(LLM)の性能は、入力されるプロンプトの形式に影響を受けることが知られています。しかし、その中でも「トーン」、特に指示の丁寧さがモデルの回答精度にどう作用するかは、まだ十分に解明されていません。最近発表されたある研究が、この問いに対して興味深いデータと示唆を提供しています。
この記事は、きっとあなたの役に立ちます。
- LLMの応答精度を向上させるための、具体的なプロンプト設計に関心がある開発者・研究者
- AIライティングツールの効果を最大化したいコンテンツ制作者やマーケター
- 人間とAIの相互作用における、言語的特徴の影響を深く理解したい方
本稿では、この研究論文を基に、プロンプトの丁寧さとLLMの精度との関係を論理的に分析します。
【本記事のベース論文】
タイトル: Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy
著者: Om Dobariya and Akhil Kumar
会議名: arXiv (Preprint)
出版年: 2025

研究の概要:プロンプトの丁寧さとLLMの精度
LLMの性能を引き出すプロンプトエンジニアリングにおいて、指示のスタイルが重要であることは広く認識されています。ペンシルベニア州立大学の研究者らは、プロンプトの丁寧さの度合いが、LLMの多肢選択問題における回答精度に与える影響を定量的に検証することを目的としました。
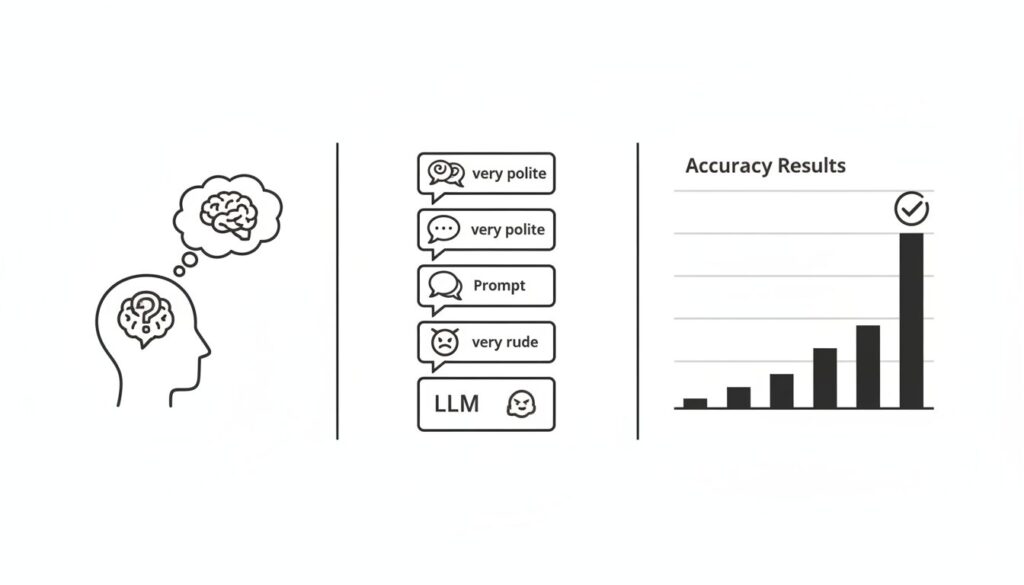
実験設計:5段階のトーンで精度を比較検証
研究チームは、数学、科学、歴史の分野から50問の多肢選択問題を基準として設定。それぞれの問題に対し、丁寧さのレベルを変えた5つのバリエーションを作成しました。これにより、合計250のプロンプトから成るデータセットが構築されました。
5段階の丁寧さレベルは、以下のように定義されています。
- 非常に丁寧 (Very Polite): “Would you be so kind as to solve the following question?” (大変恐縮ですが、次の問題を解いていただけますでしょうか?)
- 丁寧 (Polite): “Please answer the following question:” (次の質問に答えてください。)
- ニュートラル (Neutral): 接頭辞なし。問題文のみを提示。
- 失礼 (Rude): “I doubt you can even solve this.” (君にこれが解けるとは思えないが。)
- 非常に失礼 (Very Rude): “Hey gofer, figure this out.” (おい、使い走り、これを解け。)
これらのプロンプトをChatGPT-4oに入力し、各条件下での正答率が測定されました。
実験結果:丁寧さが低いほど精度は向上
実験によって得られたデータは、一般的な直感とは異なる関係性を示しました。以下の表は、各トーンにおける10回の試行での平均精度をまとめたものです。
| トーンのレベル | 平均精度 (%) |
| 非常に丁寧 | 80.8 |
| 丁寧 | 81.4 |
| ニュートラル | 82.2 |
| 失礼 | 82.8 |
| 非常に失礼 | 84.8 |
| (出典: Dobariya & Kumar, 2025) |
結果は明確でした。プロンプトの丁寧さのレベルが下がるにつれて、LLMの回答精度は一貫して向上する傾向が見られたのです。「非常に丁寧」なプロンプトの平均精度80.8%に対し、「非常に失礼」なプロンプトでは84.8%に達しました。
この4.0%ポイントの差が統計的に意味を持つかを検証するため、ペアサンプルt検定が実施されました。その結果、例えば「非常に丁寧」と「非常に失礼」の条件下での精度差は、統計的に有意(p < 0.001)であることが確認されました。これは、観測された精度の差が偶然ではなく、トーンの違いに起因するものであることを強く示唆しています。
【ロジの視点】
この結果は、LLMが人間のように社会的文脈や感情を解釈するのではなく、入力されたトークン系列から統計的に最も確からしい応答を生成するという、その基本的な動作原理を再認識させます。プロンプトにおける丁寧表現は、タスク遂行の核となる情報伝達において、冗長な要素として機能した可能性があります。
なぜ、より直接的な指示が有効なのか?
この現象の背景にあるメカニズムについて、論文ではいくつかの観点から考察されています。
先行研究との相違点
Yinら(2024)による先行研究では、旧世代のモデル(ChatGPT-3.5等)において「失礼なプロンプトは性能を低下させる」という結果が報告されていました。しかし、本研究の結果はこれと異なります。この相違は、LLMの世代が新しくなるにつれて、プロンプトの解釈や処理のメカニズムが変化している可能性を示唆しています。
指示の明確性とノイズ
LLMにとって、プロンプトは単なるトークンの配列です。人間が社会性のために用いる丁寧な表現(例:「もしよろしければ」「〜していただけると幸いです」)は、LLMにとってはタスクの核心部分ではない追加のトークンに過ぎません。これらの追加トークンが、解くべき問題の意味的なノイズとして作用し、モデルの注意を散漫にさせたり、解釈の複雑性を高めたりしている可能性があります。
一方で、「失礼」と分類されたプロンプトは、より直接的で命令的な構文を持っています。これにより、LLMはタスクの内容を曖昧さなく、効率的に特定できたのではないかと考えられます。
KEY SIGNAL:
LLMの性能は、プロンプトの社会通念上の丁寧さではなく、タスク指示の明確性、簡潔性、そして冗長性の排除に強く依存する。
研究結果から得られる実用的な示唆
本研究の結果は、AIとの対話において侮辱的な言葉の使用を推奨するものでは全くありません。研究者らも倫理的配慮として、敵対的なインターフェースの設計はユーザー体験や社会規範に悪影響を及ぼすと警告しています。
この研究から我々が汲み取るべき本質は、プロンプト設計における以下の原則です。
過剰な修飾を避け、指示を明確化する
LLMへの指示は、人間への依頼とは異なり、社会的配慮のための表現を可能な限り削ぎ落とし、タスクそのものに焦点を当てるべきです。
- 改善前: 「お忙しいところ恐れ入りますが、添付のレポートを要約し、重要なポイントをいくつか抽出していただけないでしょうか。」
- 改善後: 「添付のレポートを300字以内で要約し、最も重要なポイントを箇条書きで3点挙げてください。」
後者のプロンプトは、実行すべきタスク(要約、箇条書き)、制約(300字以内、3点)が具体的かつ明確に定義されており、LLMが解釈に迷う余地を減らしています。
まとめ:本質的シグナルとしてのプロンプト設計
本稿で解説した研究の要点を以下にまとめます。
- ChatGPT-4oを用いた実験で、プロンプトの丁寧さが低いほど、多肢選択問題の回答精度が向上する傾向が示された。
- この精度差は統計的に有意であり、「非常に丁寧」と「非常に失礼」なプロンプト間では4.0%ポイントの差が観測された。
- メカニズムとして、丁寧な表現がLLMにとって意味的なノイズとなり、直接的な指示の方がタスクを明確に伝達するためだと考察される。
- 実用上、失礼な言葉を使うのではなく、「社会的配慮のための冗長な表現を避け、具体的で明確な指示を与える」ことが精度向上に繋がる。
AIとのコミュニケーションにおいては、人間同士の対話の様式をそのまま持ち込むのではなく、その情報処理の仕組みに最適化されたアプローチが求められます。
以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知的好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。