ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
動画生成AIの実装において、私たちは常に二者択一を迫られてきました。品質を取れば計算コストが肥大化し、軽さを取れば映像は破綻する。この「重さ」と「質」のジレンマに対し、日本のスタートアップAIdeaLabが、力技ではなくアーキテクチャの刷新によって一つの回答を提示しました。2025年11月25日に公開された『AIdeaLab VideoMoE』。これは、国内初となる「ST-MoE(Spatio-Temporal Mixture of Experts)」を採用したオープンウェイトモデルです。
この記事は、次のような方へ向けて書きました。
- AIエンジニア・研究者: MoEアーキテクチャの実装詳細と、動画生成タスクへの適用効果を知りたい方。
- テクニカルディレクター: クローズドなAPI依存から脱却し、自社基盤での動画生成パイプライン構築を模索している方。
- 市場観測者: GENIACプロジェクトが輩出する国産モデルの実力と、その技術的特異性を把握したい方。
物理的なGPUリソースの限界を、論理的な設計で突破しようとする試み。その詳細を分解します。
全パラメータ稼働という「浪費」からの脱却
今回公開されたモデルの技術的核は、名称にある通り「MoE(Mixture of Experts)」、とりわけ「ST-MoE」の採用にあります。
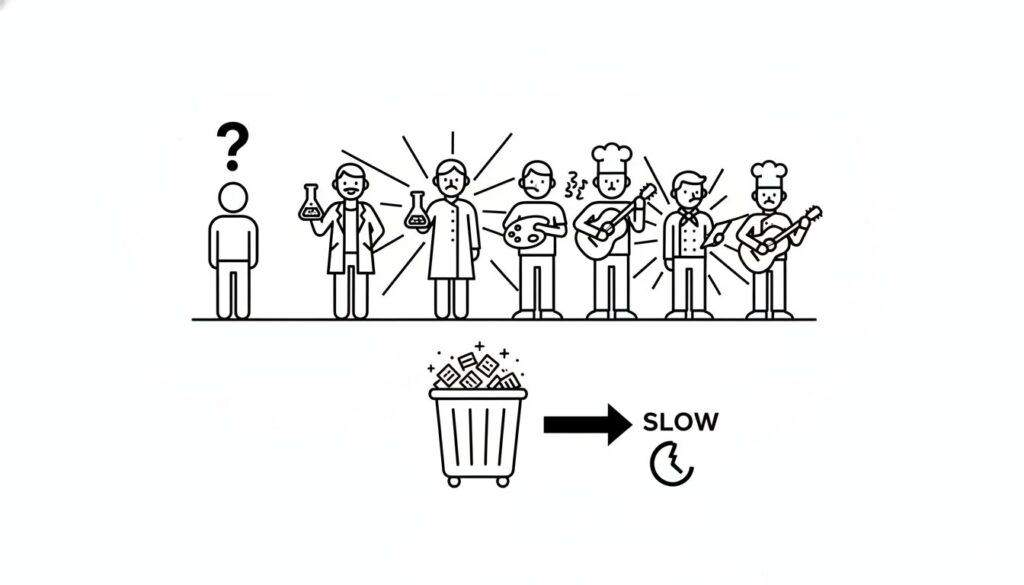
従来のDense(密)モデルでは、1つのトークンを生成するために、モデルが持つ全てのパラメータを使用していました。例えるなら、簡単な計算問題1つを解くために、数学者だけでなく、文学者や歴史学者まで全員を招集するようなものです。これは計算資源の明らかな浪費であり、推論速度の低下を招きます。
ST-MoE:空間と時間の分離統治
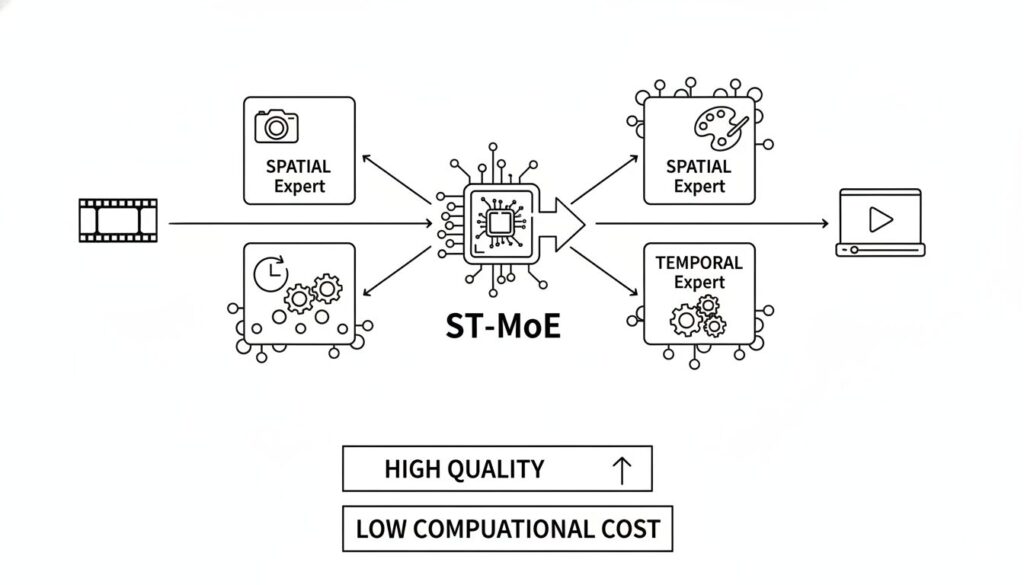
対して『AIdeaLab VideoMoE』が採用したアプローチは、必要なタスクに必要な「専門家(Expert)」だけを割り当てるスパース(疎)な構造です。特筆すべきは、動画生成特有の課題に合わせて、専門家の役割を「空間(Spatial)」と「時間(Temporal)」に明確に分離した点にあります。
動画生成タスクは複雑です。
1枚の絵としての整合性を保つ「空間的処理」。
フレーム間の連続性を維持し、物理法則に則った動きを作る「時間的処理」。
これらを混然一体として処理させるのではなく、空間担当のエキスパートと時間担当のエキスパートを用意し、ルーター(Gating Network)が動的に処理を振り分ける。結果、パラメータ総数が大きくとも、一度の推論で活性化するパラメータ数は抑制され、高品質な出力を維持したまま、計算コストを引き下げることが可能になります。
【ロジの視点】
計算資源が有限である以上、全方位的なスケールアップには限界が訪れます。処理をモジュール化し、動的にリソース配分を最適化するMoEのアプローチは、生物の神経回路網の効率性に通じる合理的な設計です。特に、情報の次元が異なる「静止画」と「動画」の処理を分離したST-MoEは、今後の動画生成基盤のデファクトスタンダードになり得る構造と言えます。
「オープンウェイト」がもたらすエンジニアリングの自由
技術以上に市場へのインパクトが大きいのは、このモデルがHugging Face上で「オープンウェイト」として、かつ商用利用可能なライセンスで公開されたという事実です。
SoraやRunwayといった海外製の先行モデルは強力ですが、その中身はブラックボックスです。API経由での利用は手軽な反面、レイテンシの制御や、出力の微細な調整、そしてコスト構造が外部依存になるリスクを孕みます。
対して『VideoMoE』は、重みそのものが手に入ります。
これは、企業が自社のプライベートクラウドやオンプレミス環境でモデルを動かせることを意味します。機密性の高いデータを外部に出すことなく処理できるだけでなく、特定のアニメーションスタイルや、自社IPのキャラクターに特化させた追加学習(ファインチューニング)を行う自由も手に入ります。
[AIdeaLab VideoMoEのサンプル出力の画像]
ブラックボックス化された「魔法の箱」を使うのではなく、エンジニアが手触り感を持ってチューニングできる「道具」が提供された。この差は決定的です。
GENIACが示した「賢い」開発競争
本モデルは、経済産業省とNEDOによる「GENIAC(Generative AI Accelerator Challenge)」の支援成果です。
GPUの調達競争が過熱する昨今、計算資源の量はそのまま開発力に直結します。しかし、リソースさえあれば良いものができるわけではありません。限られた計算資源の中で、いかに効率よく学習を進め、推論時のコストを下げるか。『VideoMoE』のアプローチは、力任せの物量作戦ではなく、アーキテクチャの工夫による「知的な」解決策を示しました。
AIdeaLabは今後、このST-MoE基盤をText-to-Video(テキストからの動画生成)へと拡張し、さらなる大規模化を目指すロードマップを描いています。テキストから動画を生成するプロセスはさらに計算負荷が高いため、MoEによる効率化の恩恵はより大きくなるはずです。
KEY SIGNAL:
動画生成AIの競争軸は、単純な「画質の綺麗さ」から、「実運用に耐えうる推論効率」と「カスタマイズ性」へ移行しています。ST-MoEの実装とオープン化は、AIを実験室から産業実装の現場へと引きずり出すためのトリガーです。
まとめ:構造改革によるブレイクスルー
『AIdeaLab VideoMoE』は、動画生成における計算の非効率性を、構造レベルで解決しようとする試みです。
この記事のポイントをおさらいしましょう。
- ST-MoEの採用: 空間処理と時間処理を専門化し、動的に計算リソースを配分することで、品質と軽さを両立。
- ブラックボックスからの脱却: オープンウェイトでの公開により、オンプレミス運用や独自のファインチューニングが可能に。
- 開発の方向性: GENIACの支援下で、計算量だけに頼らないアーキテクチャ主導の開発成果を実証。
- 拡張性: 今後のText-to-Video実装に向けた、スケーラブルな基盤技術の確立。
以下のリンクからモデルの詳細を確認し、実際の挙動をテストしてみてください。動画生成の新しい基準点が、そこにあります。
『AIdeaLab VideoMoE』

以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知的好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。