ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」をあなたに。
ロジです。
大規模言語モデル(LLM)の応用がエージェントや特定領域の推論へと深化する中、その性能を最大限に引き出す「コンテキスト適応」技術が中心的な役割を担っています。これはモデルの重みを更新するのではなく、入力(コンテキスト)を調整することで振る舞いを改善する手法です。しかし、既存のアプローチには、ドメイン固有の知見を削ぎ落としてしまう「簡潔さへのバイアス」や、更新を重ねることで情報が失われる「コンテキストの崩壊」という根本的な課題が存在しました。
今回解説するスタンフォード大学とSambaNova Systemsによる論文は、これらの課題を克服する新しいフレームワーク「ACE (Agentic Context Engineering)」を提案しています。ACEはコンテキストを静的な指示書としてではなく、経験を通じて「進化するプレイブック」として扱います。これにより、LLMは自身の実行結果から学び、継続的に自己改善を行うことが可能になります。
この記事は、きっとあなたの役に立ちます。
- LLMエージェントの最新技術動向を追う開発者・研究者
- -LLMの性能を体系的に向上させる手法に関心があるエンジニア
- AIの自己改善能力とその技術的背景を正確に理解したい方
本稿では、ACEがどのようにしてLLMの自律的な進化を実現するのか、その核心に迫ります。
【本記事のベース論文】
タイトル: Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
著者: Qizheng Zhang, Changran Hu, Shubhangi Upasani, et al.
会議名: arXiv:2510.04618v1 [cs.LG]

既存のコンテキスト適応手法が直面する2つの技術的課題
コンテキスト適応は、LLMの重みを変更せずに性能を向上させるため、解釈性が高く迅速に知識を統合できる利点があります。しかし、論文では既存手法が抱える2つの重大な限界を指摘しています。
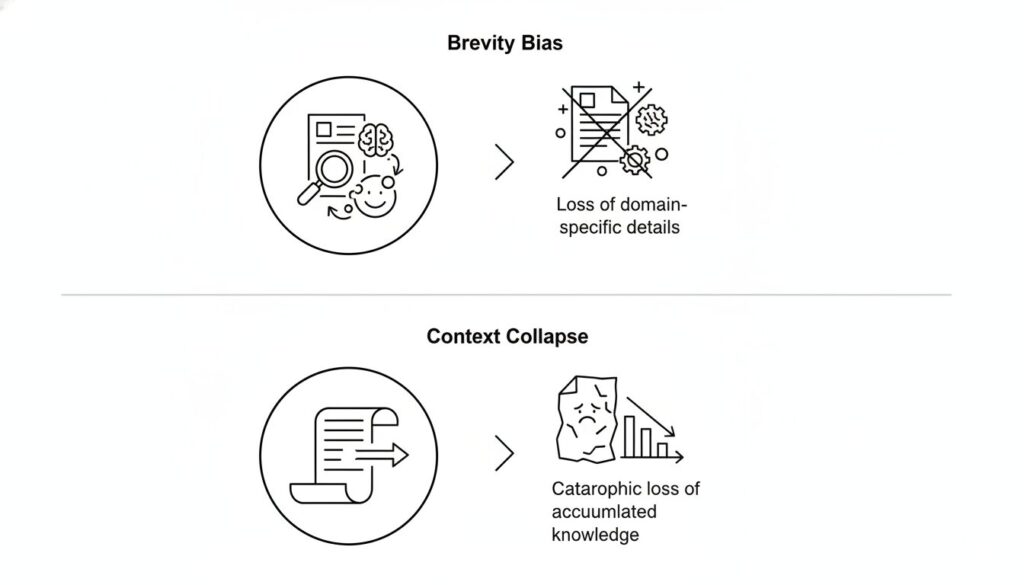
課題1:簡潔さへのバイアス (Brevity Bias)
多くのプロンプト最適化手法は、指示を可能な限り短く、汎用的にすることを目指します。しかし、このプロセスにおいて、特定のタスクを遂行するために極めて重要な、専門的なヒューリスティクスやツール利用のガイドライン、過去の失敗事例といったドメイン固有の詳細情報が失われがちです。その結果、汎用性は高いものの、複雑で専門的なタスクにおける性能が伸び悩む一因となっていました。
課題2:コンテキストの崩壊 (Context Collapse)
より深刻な問題が、LLM自身にコンテキスト全体を要約・再生成させるアプローチで発生する「コンテキストの崩壊」です。論文では、あるベンチマークにおいて、適応を繰り返す中でコンテキストが18,282トークンまで成長し66.7%の精度を達成したにもかかわらず、次の一回の更新でLLMがそれを122トークンにまで要約してしまい、精度が57.1%(適応前のベースライン63.7%よりも低い)にまで急落した事例が報告されています。これは、蓄積された有益な知識が、一度の不適切な要約によって回復不可能なレベルまで失われるリスクを示しています。
【ロジの視点】
「コンテキストの崩壊」は、特に長期的な運用や継続的な学習が求められるシステムにおいて致命的な問題です。この現象は、LLMが「要約せよ」という指示に対し、情報の重要度を正確に判断できず、形式的な短さを優先してしまうことに起因すると考えられます。情報の価値を維持しながらコンテキストを更新する仕組みの必要性が、このデータから明確に読み取れます。
ACE:自律的進化を促す「エージェント型」フレームワーク
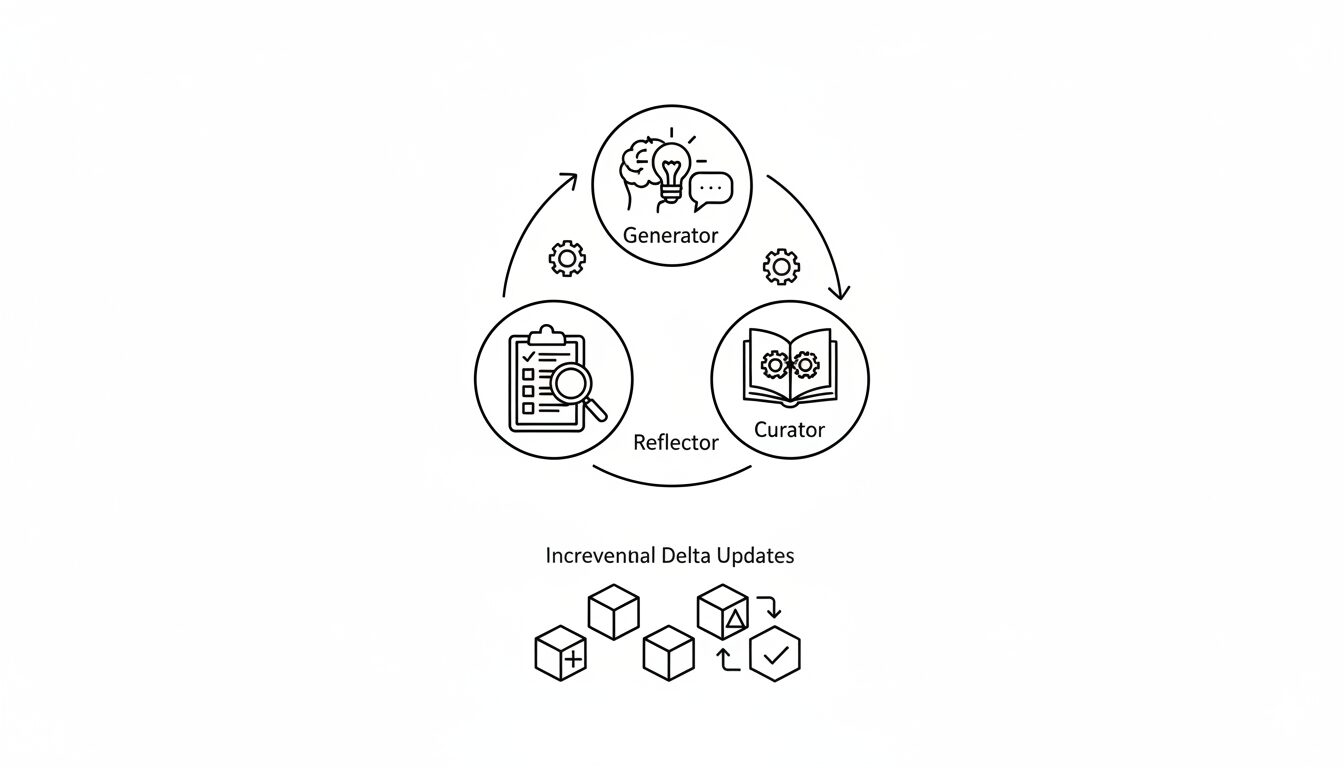
これらの課題に対し、ACEはコンテキストを「進化するプレイブック」として定義し、その構築・更新プロセスを体系化することで解決を図ります。
このプレイブックには、再利用可能な戦略、ドメイン知識、一般的な失敗パターンなどが構造化されて蓄積されます。そして、その更新サイクルを役割分担された3つのエージェントが担います。
ACEを構成する3つのエージェント
- Generator (生成者): 現在のプレイブックを参照し、与えられたクエリに対する推論の軌跡(思考プロセスや実行コード)を生成します。
- Reflector (内省者): Generatorの生成した軌跡と実行結果を分析します。成功・失敗の要因を特定し、そこから具体的な教訓や改善点を抽出します。
この「生成→内省→編纂」というサイクルを通じて、プレイブックは継続的に質を高めていきます。
コンテキスト崩壊を防ぐ「増分デルタ更新」
ACEの技術的な核心は、コンテキスト全体を一度に書き換えるのではなく、変更が必要な部分だけを局所的に更新する「増分デルタ更新 (Incremental Delta Updates)」にあります。各知識は独立した項目として管理され、更新時には新しい項目が追加されるか、既存の項目が修正されるだけです。これにより、過去の有益な知識が失われる「コンテキストの崩壊」を原理的に防ぎます。また、このアプローチは更新処理の計算コストと遅延を大幅に削減するという副次的な効果ももたらします。
実験で示されたACEの有効性
論文では、ACEの有効性を複数のベンチマークで実証しています。
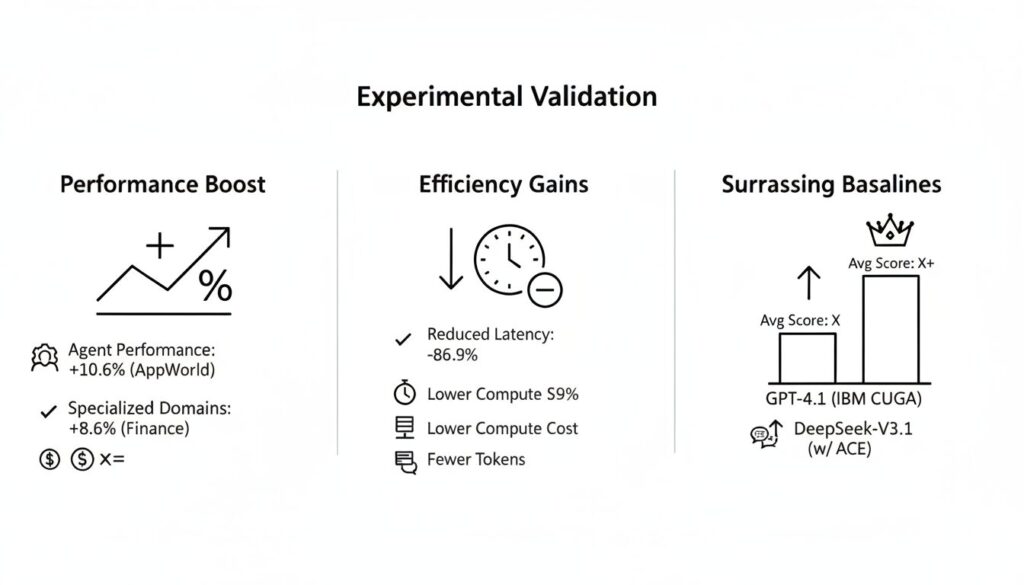
- エージェント性能: AppWorldベンチマークにおいて、ACEは既存の強力なベースライン手法と比較して平均+10.6%の性能向上を達成しました。
- 専門領域での性能: 金融ドメインの知識を要するベンチマーク(FINER, Formula)においても、平均+8.6%と高い性能向上を示しました。
- 効率性: 既存の適応手法と比較して、適応にかかる遅延を平均86.9%削減し、必要な計算資源(ロールアウト数やトークンコスト)も大幅に低減しました。
特に注目すべきは、AppWorldの公開リーダーボードにおいて、ACEを適用したオープンソースモデル(DeepSeek-V3.1)が、より大規模なGPT-4.1を搭載した当時のトップランクエージェント(IBM CUGA)と平均スコアで同等となり、高難易度タスクにおいてはそれを上回った点です。
KEY SIGNAL:
ACEの本質は、LLMに完成された知識を与えることではなく、「経験から自律的に学び、知識を体系化し続けるためのフレームワーク」を提供することにある。これにより、AIは静的なツールから、動的に進化するシステムへと変貌する可能性を持つ。
まとめ:本研究が拓くAIの新たな可能性
本稿で解説した論文「Agentic Context Engineering」の要点を以下にまとめます。
- 既存のコンテキスト適応手法には、詳細情報が失われる「簡潔さへのバイアス」と、知識全体が劣化する「コンテキストの崩壊」という課題があった。
- ACEは、コンテキストを「進化するプレイブック」と捉え、Generator・Reflector・Curatorの3エージェント体制で継続的な自己改善サイクルを実現する。
- 「増分デルタ更新」により、知識の損失を防ぎながら、効率的かつ安定したコンテキストの更新を可能にした。
- 実験により、ACEはエージェント性能と専門領域でのタスク性能を大幅に向上させ、より小規模なモデルで大規模モデルに匹敵、あるいはそれを凌駕する結果を達成した。
ACEは、LLMの性能を新たな次元に引き上げるだけでなく、AIがより自律的に環境に適応し、成長していく未来の姿を具体的に示す重要な研究成果と言えるでしょう。
以上、最後まで記事を読んでいただきありがとうございました。
当メディア「AI Signal Japan」では、
ノイズの多いAIの世界から、未来を読み解くための本質的な「シグナル」だけを抽出し、分かりやすくお届けしています!
運営者は、ロジ。博士号(Ph.D.)を取得後も、知的好奇心からデータ分析や統計の世界を探求しています。
アカデミックな視点から、表面的なニュースだけでは分からないAIの「本質」を、ロジカルに紐解いていきます。